Concept search allows you to query documents for words with a meaning similar to your search terms. Let’s look at a couple examples:
Writing NOT Code
This query implies that we should exclude or de-rank documents with phrases like “writing css” or “writing php”, preferring results with “poetry”, “fiction”, or “copyediting.”
This scenario is a ticket I received from a user of www.findlectures.com. People want ways to research the latest developments in their field, without search results being cluttered with talks that mention their interests in passing.
For a more complex example, lets say we were searching recipes:
Vegetarian Food NOT Dairy
“Vegan cooking” would be an appropriate result for this – as would be recipes for people with food allergies.
The negative search for dairy implies a hierarchy of items we wish to remove: milk, cheese and any specific types, components, or brands of these (e.g. Parmesan, whey, Kraft, respectively). It’s unlikely that the searcher has thought this far into what they want, but implicitly expect it.
For a final example:
Philadelphia, History
This search implies a geography and time range. This article about the founding of Arden, Delaware, would be an appropriate match because it is nearby.
Wordnet
The notion of a concept hierarchy brings the WordNet1 database to mind, although it is not sufficiently detailed for our purposes. Let’s suppose you wanted to search for talks, excluding politics and religion. If you start at “religion” and work down the tree, you about 200 results:
'religion', 'faith', 'organized religion', 'taoism', 'shinto', 'sect', 'religious sect', 'religious order', 'zurvanism', 'waldenses', 'vaudois', 'vaishnavism', 'vaisnavism', 'sunni', 'sunni islam', 'sisterhood', 'shuha shinto', 'shua', 'shivaism', 'sivaism', 'shiah', 'shia', 'shiah islam', 'shaktism', 'saktism', 'shakers', 'united society of believers in christ\'s second appearing', 'religious society of friends', 'society of friends', 'quakers', 'order', 'monastic order', 'society of jesus', 'jesuit order', 'franciscan order', 'dominican order', 'carthusian order', 'carmelite order', 'order of our lady of mount carmel', 'benedictine order', 'order of saint benedict', 'augustinian order', 'austin friars', 'augustinian hermits', 'augustinian canons', 'kokka shinto', 'kokka', 'karaites', 'jainism', 'high church', 'high anglican church', 'haredi', 'hare krishna', 'international society for krishna consciousness', 'iskcon', 'brethren', 'amish sect', 'albigenses', 'cathars', 'cathari', 'abecedarian', 'scientology', 'church of scientology', 'khalsa', 'judaism', 'hebraism', 'jewish religion', 'reform judaism', 'orthodox judaism', 'jewish orthodoxy', 'hasidim', 'hassidim', 'hasidism', 'chasidim', 'chassidim', 'conservative judaism', 'hinduism', 'hindooism', 'brahmanism', 'brahminism', 'established church', 'cult', 'cargo cult', 'wicca', 'voodoo', 'rastafarian', 'rastafari', 'rastas', 'obeah', 'obi', 'macumba', 'church', 'christian church', 'unification church', 'protestant church', 'protestant', 'pentecostal religion', 'nestorian church', 'coptic church', 'catholic church', ...142 more]
This list is pretty good, but far too short – Wikipedia’s list of Christian sects includes nearly 200 entries just under “types of Baptist”2.
The tree of concepts for politics has nearly nothing. Of the results it returns, none of these are what people mean by “no politics”. A political talk is determined by time – whatever is in the news now, where I’m at, is political today, and history tomorrow.
'political sympathies', 'political science', 'government', 'realpolitik', 'practical politics', 'geopolitics', 'geostrategy', 'political relation'
Word2Vec
Machine learning techniques are a compelling alternative to using a database maintained by a team, because you can rely on a computer to find patterns, and update your model as new text becomes available. Word embeddings3 are a compelling tool, Word2vec can discover implicit relationships, such as gender or country capitals. Varations of Word2vec represent word meanings from how they are used in context, using mathematical vectors.
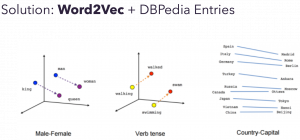
Much of the practical research I’ve found on Word2Vec and search uses it to generate synonyms. There are a few papers suggesting that Word2Vec can discover other types of relationship4 (e.g. more general/specific terms). In a Word2vec model trained on English the “nearest” term to a noun is often the plural of the term, since those two terms are often used together. I expect this would be different in a language with cases (German, Greek, Latin), as related verbs and adjectives in change their endings to match.
Use Cases
I’m using concept search to generate personalized email digests resembling the excellent Cooper Press newsletters (Javascript Weekly, Postgres Weekly, etc). Each email has unique articles from Reddit and conference talks from FindLectures.com, chosen with machine learning.

Concept search shines for users who enter multiple search terms. For “python” and “machine learning”, we really want to see pieces about scikit-learn, Tensorflow, and Keras. If we enter “java” and “machine learning”, we instead expect to see work by people using Stanford NLP or Deeplearning4j.

Rocchio Algorithm
Traditional full text search tools (Lucene) query for the presence or absence of terms, weighted by how often they occur. A variation of this is the simple and fast Rocchio Algorithm5. The Rocchio Algorithm essentially does the following:
- Run a Search
- Get common terms
- Run search again, using the terms you should have used in step 1
This improves the quality of results, and it’s very fast. There is an excellent talk on this6 by Simon Hughes / Dice.com, who has a Solr plugin that implements the algorithm7.
Here are the results when we query for articles submitted to Reddit on Python + Machine Learning:
Using the scikit-learn machine learning library in Ruby using PyCall
Pythons Positive Press Pumps Pandas
Image Recognition with Python, Clarifai and Twilio
DeepSchool.io Open Source Deep Learning course
Keep it simple! How to understand Gradient Descent algorithm
ML-From-Scratch: Library of bare bones Python implementations of Machine Learning models and algorithms
Epoch vs Batch Size vs Iterations: Machine Learning
The Rocchio algorithm does a good job here, but I suspect that Word2Vec can do better because it maintains a concept of how similar two terms are.
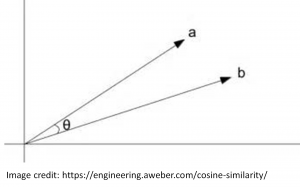
Understanding how Word2Vec defines similarity is foundational to the work we want to do with concepts: The distance between two term vectors is the cosine of the angle between them. This produces a score from 0 to 1. Like full text scores, higher is better, and it’s not mathematically valid to add the scores.
Dataset
The dataset for FindLectures.com includes machine transcriptions for most talks. When I ran Word2vec on this dataset it identified the nearest word to “code” as “coat” – a logical mistake for a machine. This suggests that Word2vec trained on articles could be used to improve machine transcription by incorporating the probability of a term in real usage. This paper
8 shows a promising example, using French language newspaper text to improve transcription of broadcasts.
Synonyms
Let’s consider a simple change to the Rocchio algorithm: use synonyms suggested by Word2vec, but incorporate the distance from the source query to the synonym as a weighting factor.
List("python", "machine", "learning").map(
(queryTerm) =>
"(" +
model.wordsNearest(
List(queryTerm), // positive terms
List(), // negative terms
25
).map(
(nearWord) =>
"transcript:" + term2 +
"^" +
(1 +
(Math.PI -
Math.acos(
model.similarity(nearWord, term2))))
).mkString(" OR ")
+ ")"
).mkString(" AND ")
This code uses the angle between terms as a boost. The following text shows the resulting Solr query looks like, The caret(^) is a boost. These boosts are multiplied by the weights Solr maintains internally (BM25)9. This accounts for how often a term occurs – really common synonyms will have essentially no effect on the output.
title_s:python^10 OR title_s:"machine learning"^10 … (title_s: software^1.21 OR title_s:database^1.20 OR title_s:format^1.18 title_s:applications^1.14 OR title_s:browser^1.14 OR title_s:setup^1.13 title_s:bootstrap^1.13 OR title_s:in-class^1.13 OR title_s:campesina^1.12 OR title_s:excel^1.12 OR title_s:hardware^1.11 OR title_s:programming^1.11 OR title_s:api^1.11 OR title_s:prototype^1.11 OR title_s:middleware^1.11 OR title_s:openstreetmap^1.10 OR title_s:product^1.10 OR title_s:app^1.09 OR title_s:hbp^1.09 OR title_s:programmers^1.09 OR title_s:application^1.09 OR title_s:databases^1.09 OR title_s:idiomatic^1.09 OR title_s:spreadsheet^1.09 OR title_s:java^1.09 … AND (…)
Here are the results for Python + Machine Learning:
Python for Data Analysis The /r/playrust Classifier: Real World Rust Data Science Andreas Mueller - Commodity Machine Learning Jose Quesada - A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and cons YOW! 2016 Mark Hibberd & Ben Lever - Lab to Factory: Robust Machine Learning Systems How To Get Started With Machine Learning? | Two Minute Papers A Gentle Introduction To Machine Learning Burc Arpat - Why Python is Awesome When Working With Data at any Scale Leverage R and Spark in Azure HDInsight for scalable machine learning Machine Learning with Scala on Spark by Jose Quesada
Here are the results for just “writing”:
Is Nonfiction Literature? "Oh, you liar, you storyteller": On Fibbing, Fact and Fabulation The Value of the Essay in the 21st Century Making the Case for American Fiction: Connecting the Dots Siri Hustvedt in Conversation with Paul Auster Issues Related to the Teaching of Creative Writing Aspen New York Book Series: The Art of the Memoir H.G. Adler - A Survivor's Dual Reverie Sixth Annual Leon Levy Biography Lecture: David Levering Lewis Contemporary Writing from Korea
These results look really good – we’ve removed all the “code” oriented results.
In my first implementation I used the cosine similarity as the boost, rather than the angle it represented. This is almost as good, but it returned an article titled: “Re-writing, Re-reading, Re-thinking – Web Design in Words”. Clearly this has the correct terms, but is not actually about the topic we’re looking for.
Aboutness
To improve these results further, I’d like to measure whether the document is “about” the query terms. An easy way to do this is to average all the terms in the query and document, and compute the cosine similarity
10. Per the linked paper from Microsoft Research, this is a good technique if it is used to re-shuffle top results (i.e., you would not want to replace full text search with this).
val queryMean = model.getWordVectorsMean(List(“writing”))
val mean = model.getWordVectorsMean(NLP.getWords(document._1))
val distance = Transforms.cosineSim(vec._2, queryMean)
Graphically, we’re comparing the “average” for the document to the “average” for the query:
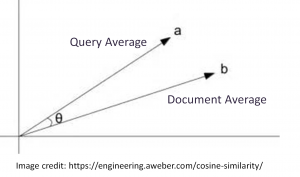
This is not fast – computing all of these term vectors and averaging them took 5 minutes 45 seconds on my machine with 16 parallel threads. This could be significantly improved by pre-computing the averages for each document and running on a GPU.
Here are the new results for “writing” (the previous result, re-sorted by “aboutness”):
Issues Related to the Teaching of Creative Writing: 0.43 Autobiography: 0.41 Contemporary Indian Writers: The Search for Creativity: 0.41 Marjorie Welish: Lecture: 0.40 History and Literature: The State of Play: A Roundtable Discussion: 0.40 Critical Reading of Great Writers: Albert Camus: 0.40 Daniel Schwarz: In Defense of Reading: 0.39 The Journey To The West by Professor Anthony C. Yu: 0.39 Blogs, Twitter, the Kindle: The Future of Reading: 0.39
Again, these look good.
Overlapping Search Terms
Some People who set up email alerts enter all of their interests (Art, Hiking), and some enter terms that modify each other (Python, Programming). We need to identify whether each term is related so that we can choose between “AND” and “OR” in the queries we generate.
A simple approach to this is to compute the distance between each query term and segment them into clusters.
terms.map(
(term1) =>
terms.map(
(term2) => (term1, term2)
)
).flatten.filter(
(tuple) => tuple._1 < tuple._2
).map(
(tuple) =>
(tuple._1, tuple._2, w2v.model.get.similarity(tuple._1, tuple._2))
)
Here are the distances for our example:
distance(programming, python): 0.61 distance(art, hiking): 0.1
Topic Diversity
While we’re now getting good results we often see articles on the same subject. For an email list dedicated to learning, it’s no use giving people the same article written multiple times.
In one email a user who chose “writing” as a topic got these two talks back:
A Conversation with David Gerrold, Writer of Star Trek: The Trouble with Tribbles (58 minutes) Star Trek: Science Fiction to Science Fact - STEM in 30 (28 minutes)
Even worse, an alert for Python returned these results, which are all re-written versions of the same article:
Pythons Positive Press Pumps Pandas Why is Python Growing So Quickly? Python explosion blamed on pandas
Improving the diversity of search results is a fascinating problem. If this was an e-commerce site, producing varied results for a broad search like “shoes” gives the users hints about what a site has to offer, as well as prompts to refine the search.
Solr can do k-means clustering of documents around phrases it discovers11 using Carrot212 – we could improve diversity by choosing a talk from each cluster.
The clusters I get for “transcript:python” are as follows:
Deal with Unicode False Really Are Equal to True Interactive Debugger Outputs a Path Piece of Fortran Python 2.7 Point 10 Embedding Situation Android App Awesome Capability Binary Multiply Depended on Pandas have Pandas
Each of these clusters has a list of talks within it. Here is what we get if we pick a talk per cluster:
Google I/O 2011: Python@Google Porting Django apps to Python 3 Python, C, C++, and Fortran Relationship Status: It’s Not That Complicated Supercharging C++ Code with Embedded Python Rules for Radicals: Changing the Culture of Python at Facebook Python for Ruby Programmers Saturday Morning Keynote (Brett Cannon) All Things Open 2013 | Jessica McKellar | Python Foundation
This approach is really fast, but difficult to combine with the prior techniques (pick N results, reshuffle).
A Word2vec alternative could do this: Pick the top result, then find least related result. Average these two, then find the next most unrelated talk.
We’re doing the following comparison iteratively:

Again this was a bit slow – 1 min, 30 seconds @ 16 parallel threads.
To prove this works I changed the query to “python and pandas” to make it harder – that guarantees the original three articles show up.
Python explosion blamed on pandas: 1.0 Considering Python's Target Audience: 0.97 Animated routes with QGIS and Python: 0.97 I can't get some SQL to commit reading data from a database: 0.97 Using Python to build an AI Twitter bot people trust: 0.96 Getting a Job as a Self-Taught Python Developer: 0.96 Download and Process DEMs in Python: 0.96 How to mine newsfeed data and extract interactive insights in Python: 0.94 Differential Equation Solver In MATLAB, R, Julia, Python, C, Mathematica, Maple, and Fortran: 0.86 My personal data science toolbox written in Python: 0.75
Conclusion
In general, each technique builds upon the last by obtaining the top results and re-shuffling. Adding more computing resources improves more relevance, but it takes some time to build and retrain Word2vec. In the next iteration of this, I’m intending to explore generating sequences of talks that build on each other, as well as dealing with geography (“history of philadelphia”).
- https://wordnet.princeton.edu/ [↩]
- https://en.wikipedia.org/wiki/List_of_Christian_denominations [↩]
- https://en.wikipedia.org/wiki/Word_embedding [↩]
- http://scholarworks.uno.edu/cgi/viewcontent.cgi?article=3003&context=td [↩]
- https://en.wikipedia.org/wiki/Rocchio_algorithm [↩]
- https://www.youtube.com/watch?v=-uiQY2Zatjo&index=31&list=PLU6n9Voqu_1FMt0C-tVNFK0PBqWhTb2Nv [↩]
- https://github.com/DiceTechJobs/RelevancyFeedback [↩]
- https://www.researchgate.net/publication/224319730_Improving_language_models_by_using_distant_information [↩]
- http://opensourceconnections.com/blog/2015/10/16/bm25-the-next-generation-of-lucene-relevation/ [↩]
- https://arxiv.org/pdf/1602.01137v1.pdf [↩]
- https://lucene.apache.org/solr/guide/6_6/result-clustering.html [↩]
- http://project.carrot2.org/ [↩]