At the Lucidworks Solr/Lucene Revolution conference, I saw several speakers discuss search suggestions – this includes typeahead, the “you might also like…” feature on Google, or the “up next” style suggestions Youtube presents.
One of my goals for my project, FindLectures.com, is to support users who want to stumble across something interesting. I don’t use popularity measures in ranking as this locks you in to recommending speakers who are currently well-known. For instance, James Baldwin has recently regained some popularity due to a documentary, but was always a compelling speaker.
Before solving this problem, I’d like to explore how other search engines do recommendations. Amazon does makes recommendations based on other people’s past purchase behavior. E.g., if you search for the famous Ron Chernow book on Alexander Hamilton, they recommend authors who are read by the same people:

By contrast, Google looks at the sequences of searches that users type in. If you type “Ron Chernow” and then “Ron Chernow Alexander Hamilton”, they will eventually pick up on the pattern and include the second term in their recommendations.

Both of these approaches assume that you have a lot of users, and that you want to extract knowledge from your users, which may require your application to violate their privacy. It is also impractical for applications with malicious users (i.e. a lot of fraud or SEO activity), or users who are indifferent to your application (enterprise search).
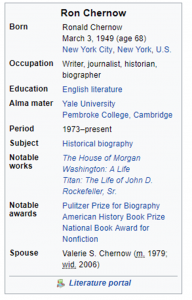
A tempting third option is to use Wikipedia. Clearly they have useful information about this author, since they have a list of his books:

Unfortunately Wikipedia also has a lot of noise. For generating suggested authors for instance, I don’t think it’s useful, for instance, to list Ron Chernow’s honorary degrees.

The way I’ve chosen to solve this is to use a pre-trained Word2Vec model, which has been run against Wikipedia. Word2Vec generates mathemematical vectors based on the contexts in which words are used. Word2Vec is famous for learning relationships between terms. In one of the canonical examples, it learns the concept of gender.

These vectors can be added – one of the canonical examples is that “king – man + woman” is approximately equal to queen.
Normally this model is trained to learn individual words, but the model trained on Wikipedia articles uses IDs where there are links to represent multi-word phrases.
Below, you can see an example in the Wikipedia dataset where the addition and subtraction works. This result is the top four closest Wikipedia articles to “Gloria Steinem”, where we first subtract “Person” and add “Ideology.” It’s important to recognize that these are not value judgments by the algorithm – these are phrases that are mentioned in the same contexts.
DBPEDIA_ID/Gloria_Steinem - DBPEDIA_ID/Person + DBPEDIA_ID/Ideology ~= DBPEDIA_ID/Marxist_Feminism DBPEDIA_ID/Radical_Feminism DBPEDIA_ID/Feminist_Movement DBPEDIA_ID/Feminist_Theory
In the model these are stored as IDs, so when you use this model, you need to do a lookup to get the display values.
DBPedia is the data-equivalent of Wikipedia. You can think of it being like the cards on the side of Wikipedia articles. This includes a ton of trivia – for instance, you can look up which U.S. Presidents were left or right handed.
The lookups on DBPedia are done using a SQL-like language called SPARQL- this allows us to determine whether an identifier represents a person, place, or thing, and what the Wikipedia article title for the ID is.
select ?property ?value
where {
?value .
FILTER(
LANG(?value) = "" ||
LANGMATCHES(LANG(?value), "en"))
}
If we look up the IDs and pick the top people closest to “Martin Luther King, Jr,” we get the following results:
Martin Luther King III Martin Luther Ralph Abernathy James Bevel Malcolm X Fred Shuttlesworth Stokely Carmichael
This result looks pretty good – the only result that doesn’t fit is “Martin Luther”, but that seems like an understandable mistake. This isn’t making any statements about the nature of the relationships – this algorithm is saying that these people are are mentioned in the same contexts.
If instead we look for a topic, we also get pretty good results:
South Vietnam North Vietnam Military history of Australia during the Vietnam War Laotian Civil War Republic of Vietnam First Indochina War Cold War
Returning then to our original example, Ron Chernow, we can get a list of names of people who might be related. This is how they are stored in Solr:
Solr Core: Suggestions
Columns:Term (text), Suggestion (json)
Term: Ron Chernow
Suggestions: “[‘Joseph Ellis’, ‘Gordon S. Wood’, ‘Kevin Phillips’, ‘David Brion Davis’, ‘David Levering Lewis’, ‘Paul Collier’, ‘James B. Stewart’, ‘Ron Rosenbaum’, ‘Jean Edward Smith’, ‘Gordon A. Craig’]”
When these are stored in the FindLectures.com index, it retains just the JSON of these suggestions, as that makes it easy to render a user interface.
The authors that this returns are a mixture of historians, professors, and biographers, with a general leaning toward people who write about revolutionary war history.

To get these results, a full text query is run against the search term stored in the index (a Wikipedia article title), so if you type something in that is close to what is in the suggestion index, you still get results. This is configured to be case insensitive and to ignore accent marks.
At the Solr/Lucene Revolution conference I mentioned above, several speakers discussed challenges around search recommendations in their domains:
Home Depot: Many searches are regional and seasonal, so the data model maintains month/quarter, and they run a clustering algorithm on the U.S.
Vegas.com: They have a relatively small number of items to search, but many that are hard to spell (celine dion, cirque de soleil). A large population of their customer base are “cognitively impaired” people on mobile devices.
E-commerce sites: Users often switch contexts rapidly, so everyone says not to give in to the temptation to model someone’s train of thought with machine learning. E.g. if someone searches Home Depot for “nails” they are just as likely to switch to “washing machines” as “hammers. Many e-commerce sites also use tools to manage tons of manually constructed rules (regexes + suggestions).
Recommended searches are one specific use case within the broader landscape of search. While Google and Amazon have made it look easy, search engines are a challenging and fascinating topic with a ton of potential for innovation.